
aubib.de goes semantic!
 |
09. Dezember 2018
|
Gedankensprünge,
Projekt,
Fachliches
|
09. Dezember 2018
|
Gedankensprünge,
Projekt,
Fachliches
tl;dr (too long; didn't read):
aubib.de ist jetzt so aufbereitet, dass Suchmaschinen die Inhalte auch verstehen und nicht nur anzeigen können!
Das Semantische Web - gehört hat es wohl schon jeder, meistens hat einem irgendjemand ehrfürchtig davon erzählt, ohne selbst so genau zu wissen, was das eigentlich ist. Dabei ist die Logik und der Sinn dahinter eigentlich recht simpel und vor allem für Bibliothekare, wenn man es genauer betrachtet, fast schon Routine!
1) Die Idee
Wieso funktionieren Bibliothekskataloge? Weil Bibliothekare jede Ressource in die Hand nehmen und (zu?) genau beschreiben, was es damit auf sich hat. Damit generieren wir Metadaten, Daten über das Medium also. Diese Daten kann man miteinander verknüpfen, wodurch wir zum Beispiel Filter nach Jahreszahlen, Autoren usw. anbieten können.
Die Idee des Semantischen Webs ist eigentlich eine ganz ähnliche, nur auf einem viel tieferen Level. Sinn ist es, nicht ganze Ressourcen zu beschreiben, sondern die Inhalte der Ressource direkt. Wenn auf einer Website also der folgende Satz steht: "Am Fachbereich wird viel zu viel über Katzen gesprochen! ( *hust* )", dann würde eine (Such)Maschine diesen Satz zwar crawlen können und möglicherweise sogar anzeigen, wenn ein Nutzer nach "Katze" sucht. Das basiert dann aber nur darauf, dass der Suchbegriff "Katze" auch in dem Satz vorkommt, VERSTEHEN kann die Maschine nicht, was eine Katze ist. Und da setzt Semantik an!
2) Oh mein Gott, wie cooool, wie geht das?
Man versucht also der Maschine zu erklären, was eine Katze ist. Dafür muss man erst einmal beschreiben, was ein Säugetier ist. Und dafür vielleicht, was ein Lebewesen ist? Solche Erklärungen kann man in einer "Ontologie" festlegen, die versucht, einen bestimmten Ausschnitt der Realität abzubilden, wie eine Klassifikation ja auch - nur eben feiner.
Eine Katze könnte man z.B. so verorten:
ETWAS > Lebewesen > Säugetier > Katzen
Und da wir uns in der Welt von HTML und XML-Tags bewegen, würde man den Satz in HTML so auszeichnen:
<p>Am Fachbereich wird viel zu viel über <span typeof="Katzen">Katzen</span> gesprochen! ( *hust* )</p>
Damit kann die Maschine erkennen, dass von einer "Katze" gesprochen wird und auch einordnen, dass eine Katze ein Lebewesen ist.
Natürlich kann man sowas noch spezifischer mit Attributen ausdrücken:
<p>Am Fachbereich wird viel zu viel über <span typeof="Katzen"> <span property="color">braune</span> Katzen</span> gesprochen! ( *hust* )</p>
Damit würde man ausdrücken, dass über BRAUNE Katzen zu viel gesprochen wird ( *hust* ), da es ja aber um alle Katzen geht, lassen wir das mal weg.
Das Format, in dem wir oben ausgezeichnet haben, nennt sich übrigens "RDFa", darüber hinaus gibt es aber auch noch andere, z.B. das momentan bevorzugte "JSON LD", in dem wir auch die meisten Inhalte auf aubib.de aufbereitet haben. Nur beim Blog musste auf RDFa zurückgegriffen werden, weil die Inhalte dynamisch und teilweise intern generiert werden - mit Sicherheit kann man im Nachheinein jedenfalls sagen: Der TYPO3-Blog ist nicht für's Semantic Web gedacht ;)
Übrigens, ausgestattet sind bei uns jetzt Home, Blog, Wie-, Wo-, HföD- und die Tipps&Tricks-Seite! Gerne im Quelltext stöbern!
3) Okay, bis grad fand ich's cool, aber nicht so ausführlich bitte.
Natürlich gibt es da noch einiges drumrum, man muss eine Ontologie auswählen ( für uns war das www.schema.org , weil die von den großen Suchmaschinen gemeinsam definiert wurde ),
viele Klassen und Attribute richtig definieren, aaaber kurz gesagt:
Die Möglichkeiten, die sich daraus ergeben sind immens! Google führt zum Beispiel einen "Knowledge Graph", in dem alle vorkommenden Konzepte aus dieser Ontologie miteinander verknüpft sind. Daraus entstehen z.B. die ausführlichen Suchergebnisse in der Box rechts. Würden wir unseren Satz von oben noch weiter auszeichnen und jemand nach dem Fachbereich googlen, könnte in der Box rechts zum Beispiel stehen: "Gesprächsthemen: viel zu viel über Katzen" - oder sowas ähnliches ;)
Und auch für die Wissenschaft kann das große Auswirkungen haben, mehr dazu zum Beispiel in diesem Blogbeitrag zum Thema Open Research Knowledge Graph an der TIB Hannover.
4) Naja, vielleicht schau ich's mir doch mal an?
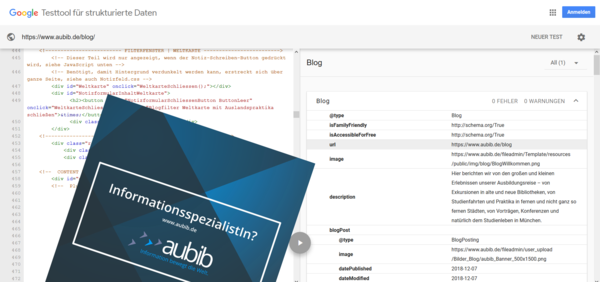
Mit dem Google Structured Data Testing Tool kann man sehr gut arbeiten und korrigieren, hier zum Beispiel die Ansicht unseres Blogs: search.google.com/structured-data/testing-tool
Für den Einstieg müssen aber erstmal Tutorials zu Ontologien, RDF und JSON LD her, die hier sind ganz verständlich finde ich:
Linked Data & JSON LD: json-ld.org/learn.html
Structured Data: developers.google.com/search/docs/guides/intro-structured-data
Linked Data & schema.org-Ontologie: schema.org
Viel Spaß, und wie immer: Erfahrungen, Meinungen und Morddrohungen in die Kommentare! :)
Keine Kommentare mehr möglich!
14. Dezember 2018
Dankeschön, macht aber auch ziemlich Spaß! ;)
14. Dezember 2018
geiles Zeug macht Ihr!